Ancient Greek and Latin Dependency Treebank (AGLDT): the earliest treebank for Ancient Greek and Latin, annotated based on dependency syntax
Conspiracy theories dataset (Access: Please contact Tianyi Zhao) This dataset is a collection of comments extracted from Reddit. It can be used to train a machine learning model for a task of binary classification. The data is labeled as either "conspiracy" or "not conspiracy" and is of a political domain.

Corpus of Historical Low German (CHLG): Penn Treebank-style annotated version of the Heliand, an Old Saxon gospel harmony written in alliterative verse:
Corpus of US Bills (CoUSBi): CoUSBi consists of all enacted, legislative bills related to education for the years 2007 to 2015 from the US states North Carolina and New Mexico. The bills are formatted according to the TEI standard and are also annotated for Named Entities. (in-house resource)
Cross-linguistic argument corpora annotated with Inference Anchoring Theory: Set of corpora annotated with Inference Anchoring Theory, a theoretical framework for argument annotation across genres and languages. (in-house resource)
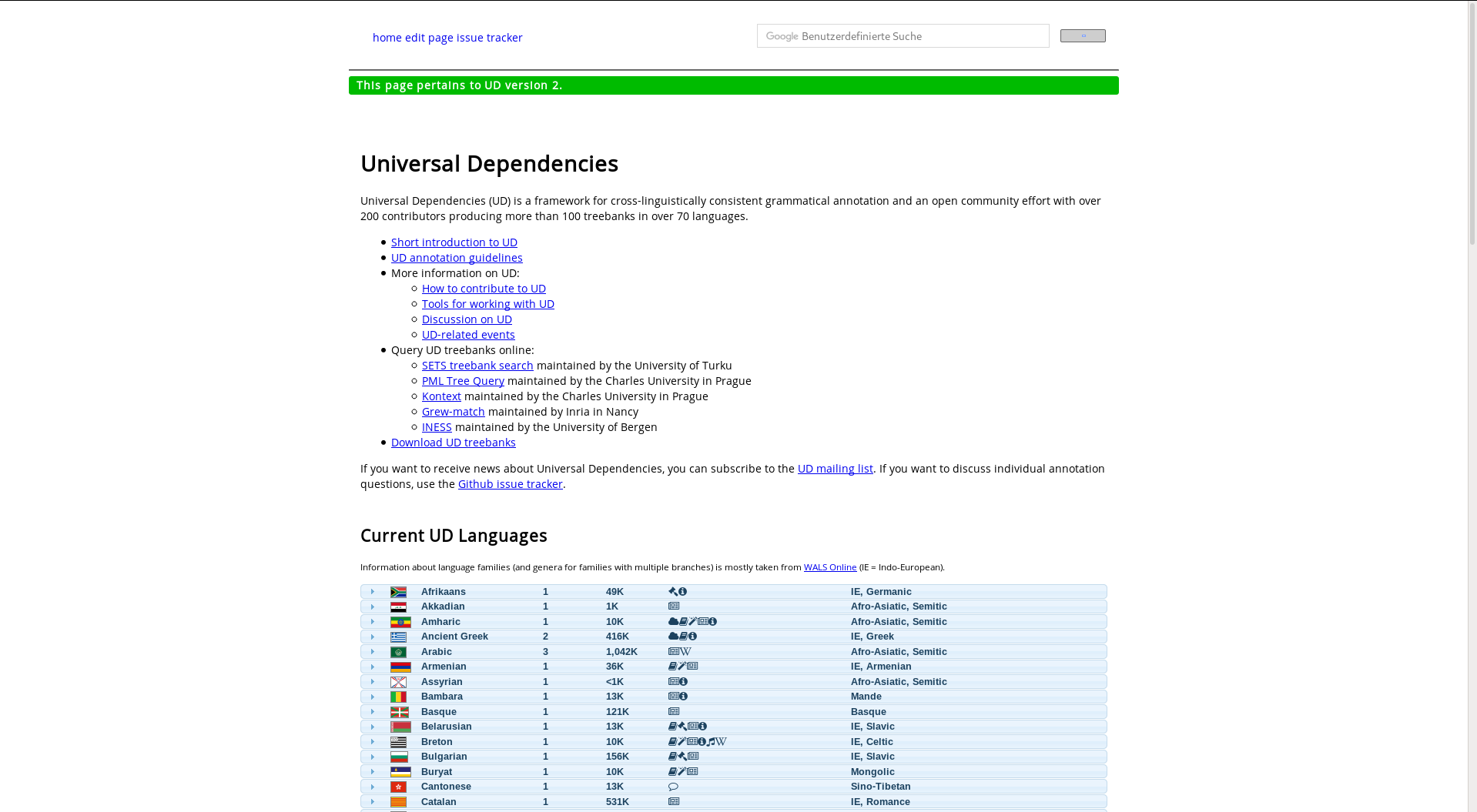
Dependency Treebanks: General overview of dependency treebanks for various languages and language families.
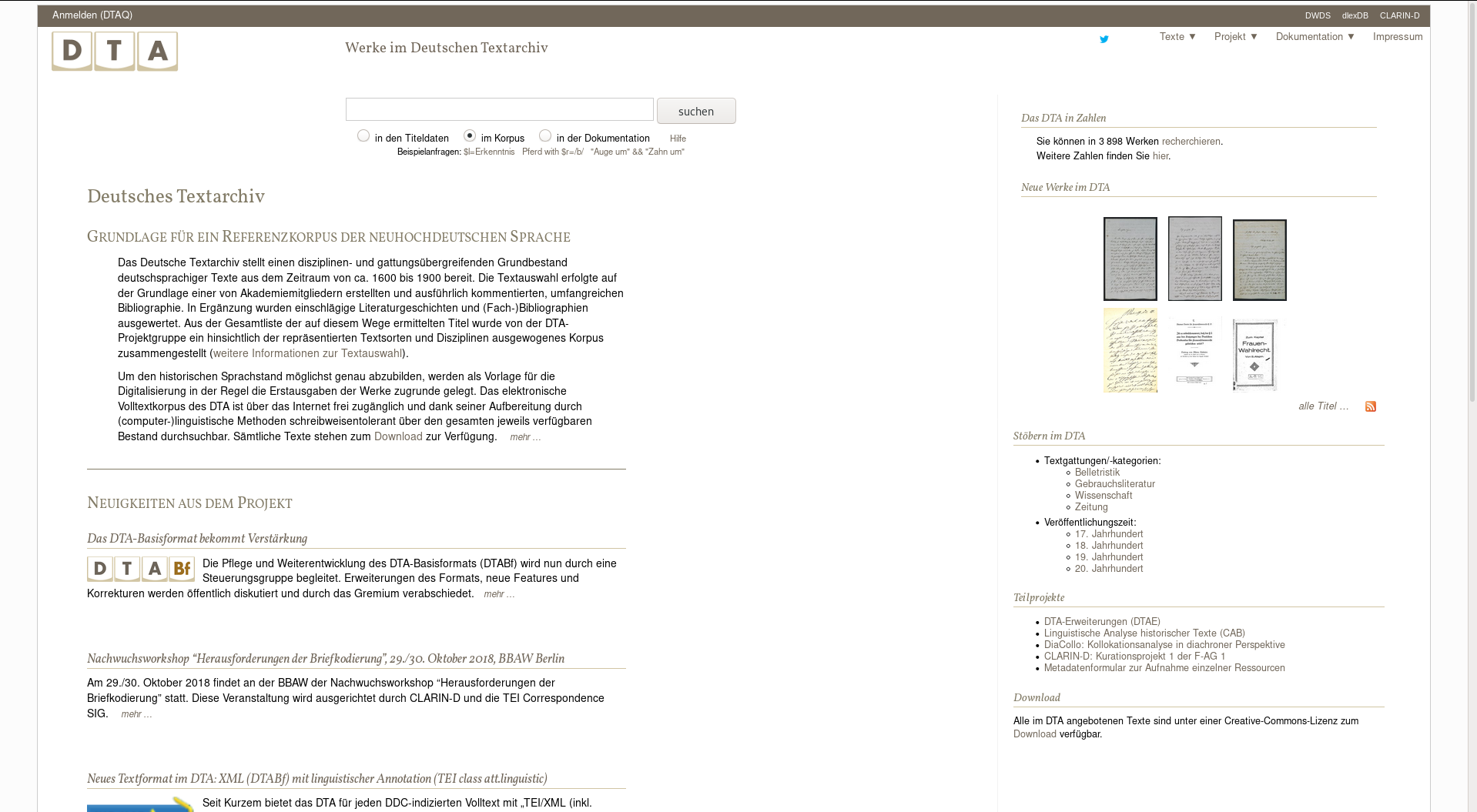
Deutsches Textarchiv (DTA): The German Text Archive presents online a selection of key German-language works in various disciplines from the 17th to 19th centuries. The electronic full-texts are indexed linguistically and the search facilities tolerate a range of spelling variants.
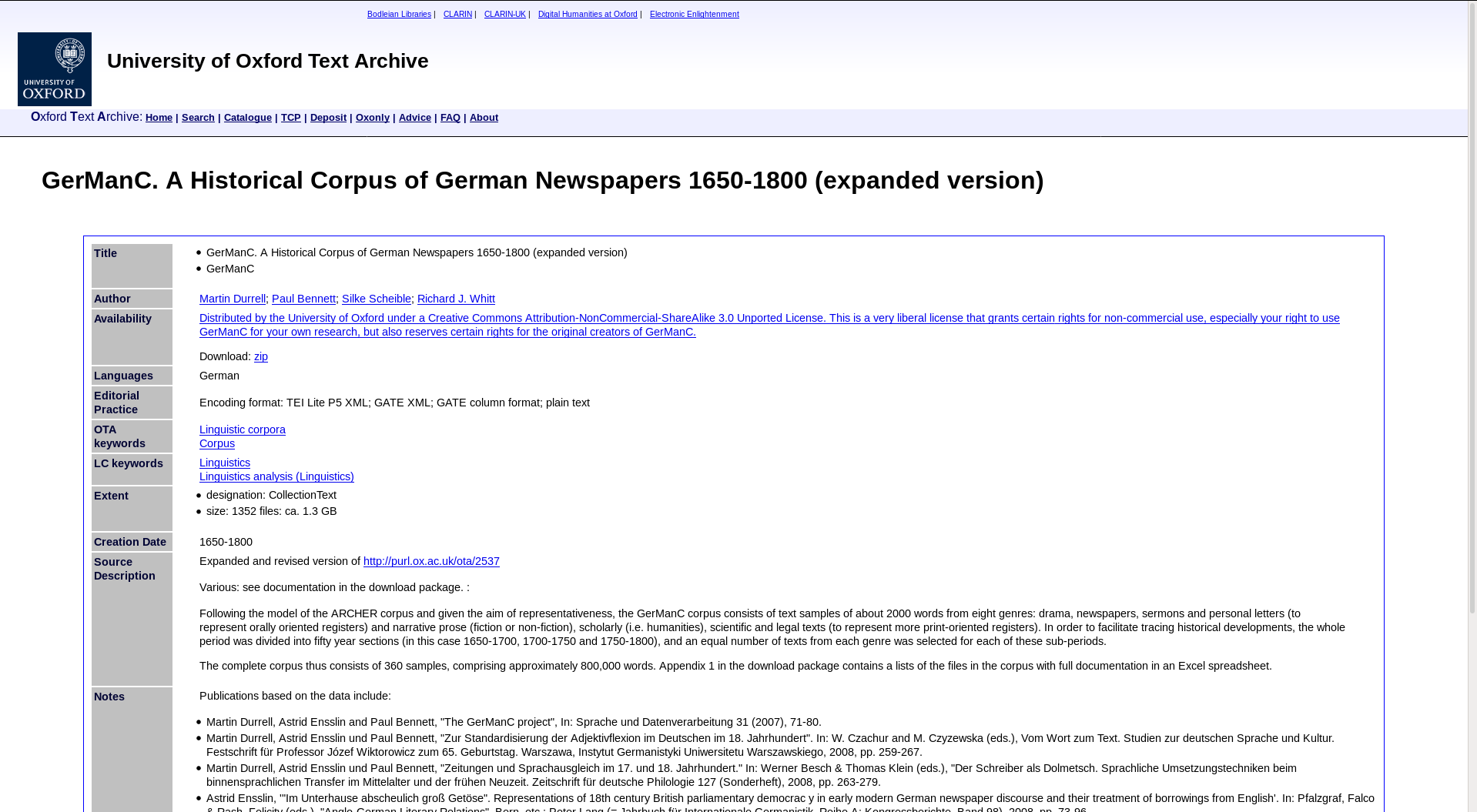
GerManC: The ultimate aim of the project is to compile a representative historical corpus of written German for the years 1650-1800. This is a crucial period in the development of the language, as the modern standard was formed during it, and competing regional norms were finally eliminated. A central aim of the project is to provide a basis for comparative studies of the development of the grammar and vocabulary of English and German and the way in which they were standardized.
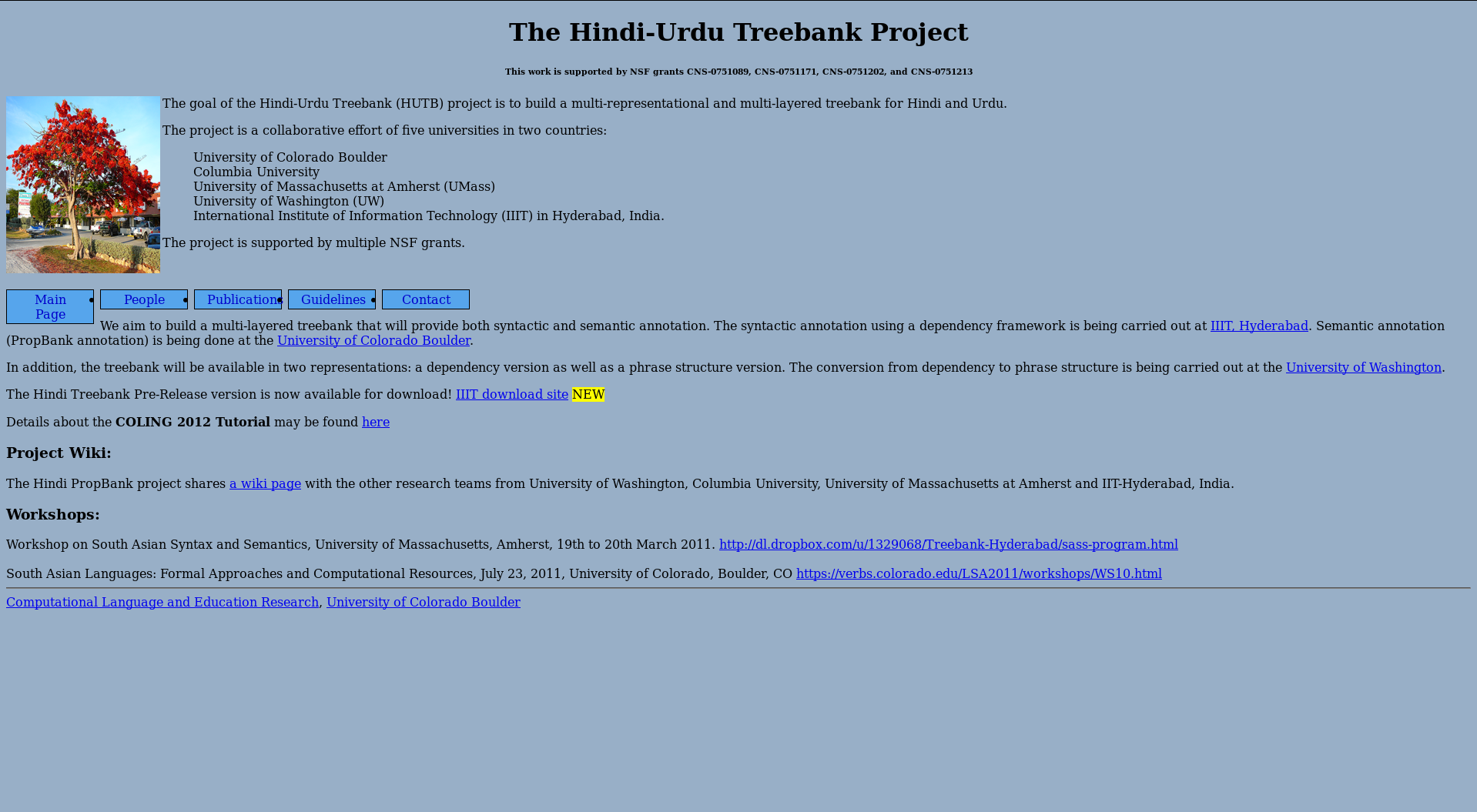
HUTB: the goal of the Hindi-Urdu Treebank (HUTB) project is to build a multi-representational and multi-layered treebank for Hindi and Urdu.
Icelandic Parsed Historical Corpus (IcePaHC): Syntactically annotated corpus in the Penn Treebank format with 61 text extracts covering all attested stages of Icelandic from the 12th to 21st century.
KRoQ: a parallel, multilingual corpus of French, Spanish and Greek Bible translations. The questions included in the text are annotated for their type, i.e. whether they are information-seeking or non-information seeking (e.g. rhetorical). The corpus can be used for training a question-type classifier or for the theoretical study of the annotated questions. (in-house resource)
Multi-Genre NLI: a crowd-sourced collection of 433k sentence pairs annotated with textual entailment information. The corpus is modeled on the SNLI corpus, but differs in that it covers a range of genres of spoken and written text, and supports a distinctive cross-genre generalization evaluation.

OpenSubtitles2016: a collection of translated movie subtitles in 65 languages. The subtitles are provided as a parallel corpus, with a total of 1,850 bitexts.
Pragmatic Resources of Indo-European Languages (PROIEL): Treebank of ancient Indo-European languages annotated according to dependency grammar framework.

Sentences Involving Compositional Knowledge (SICK): The SICK data set consists of about 10,000 English sentence pairs annotated for relatedness and entailment relations by means of crowdsourcing techniques.
Stanford Natural Language Inference Corpus (SNLI): a collection of 570k human-written English sentence pairs manually labeled for entailment, contradiction, and neutrality, supporting the task of natural language inference (NLI), also known as recognizing textual entailment (RTE).

Stanford Politeness Corpus: The corpus contains requests of people in the Wikipedia community of editors and the Stack Exchange question-answer community. The requests are annotated for their politeness, from "very polite" to "very impolite"
TextGrid Bibliothek: The Digital Library at zeno.org represents an extensive collection of German texts in digital form, ranging from the beginning of the printing press up to the first decades of the 20th century. The collection is of particular interest to German Literature Studies as it contains virtually all the important texts in the canon and numerous other texts relevant to literary history whose copyright has expired. The same applies to Philosophy and Cultural Studies as a whole. For the most part, the texts are taken from textbooks and can therefore be cited, as well as the remaining texts, which predominantly stem from the digitalisation of first editions.

Tiger Corpus: The TIGER Corpus (versions 2.1 and 2.2) consists of app. 900,000 tokens (50,000 sentences) of German newspaper text, taken from the Frankfurter Rundschau. The corpus was semi-automatically POS-tagged and annotated with syntactic structure. Moreover, it contains morphological and lemma information for terminal nodes.
WhFinCor: WhFinCor is a sub-corpus of the DWDS core corpora (https://www.dwds.de/r). It comprises 479 German sentences with a final wh-word and a period. About 57% of the material are sluices (elided embedded questions, e.g. Ed tötete jemanden, aber ich weiß nicht, wen [ ]. (“Ed killed someone, but I don’t know who [ ]”) ) and annotated as such. Furthermore, information about negation, embedding verbs and more surface-syntactic cues are annotated. WhFinCor can be used to investigate the phenomenon of sluicing or wh-final sentences in general.
WordNet is a large lexical database of English. Nouns, verbs, adjectives and adverbs are grouped into sets of cognitive synonyms (synsets), each expressing a distinct concept. Synsets are interlinked by means of conceptual-semantic and lexical relations.