ARCHER: Archer is a multi-genre corpus of British and American English covering the period 1600-1999, first constructed by Douglas Biber and Edward Finegan in the 1990s. It is managed as an ongoing project by a consortium of participants at fourteen universities in seven countries.
Brown: The Brown Corpus was the first computer-readable general corpus of texts prepared for linguistic research on modern English. It was compiled by W. Nelson Francis and Henry Ku era at Brown University in the 1960s and contains of over 1 million words (500 samples of 2000+ words each) of running text of edited English prose printed in the United States during the calendar year 1961.
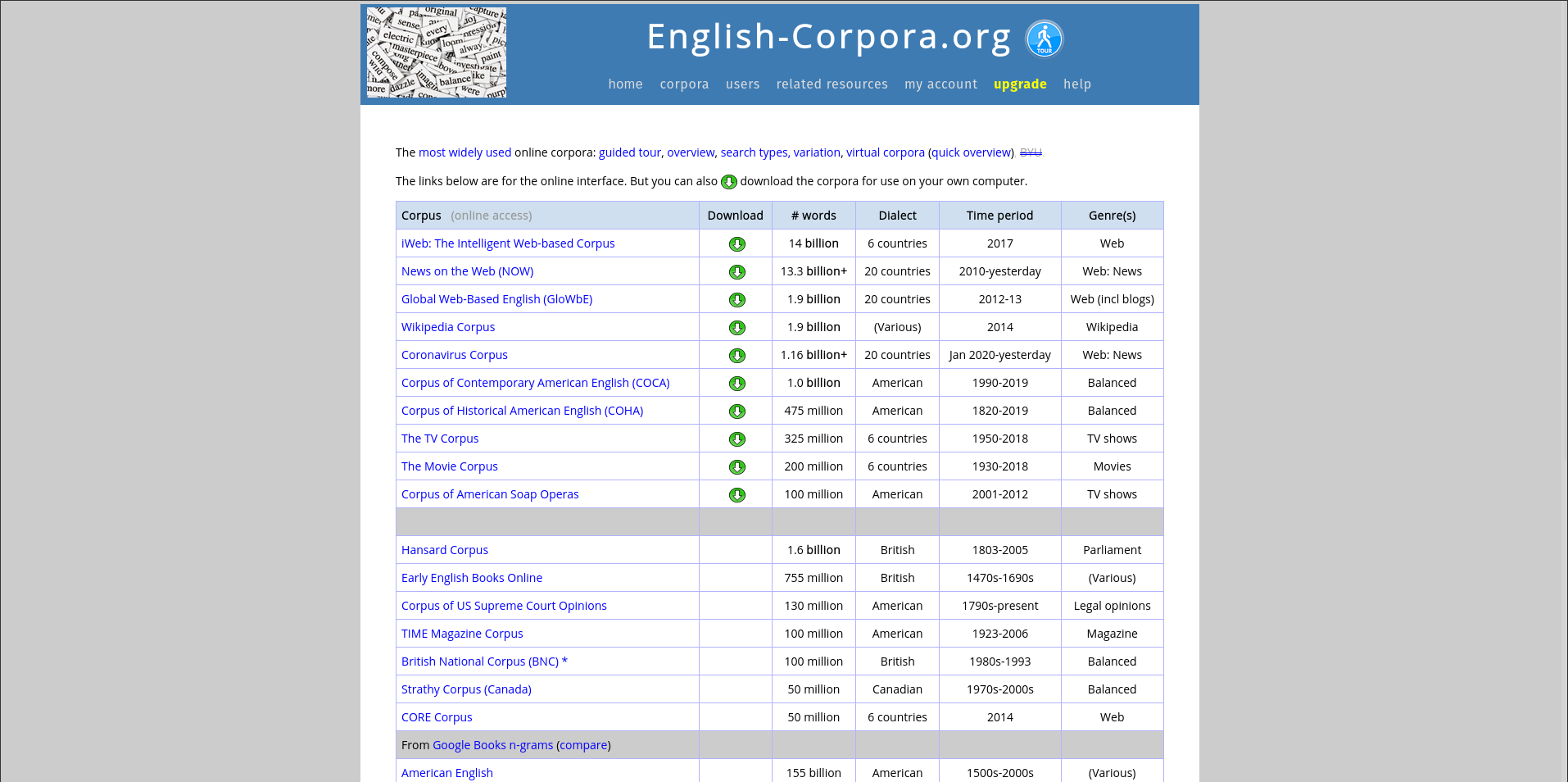
English Corpora English-corpora.org (formerly BYU corpora) is a collection of annotated English corpora. It also offers resources such as n-gram and frequency lists.
GermaNet: GermaNet is a lexical-semantic net that relates German nouns, verbs, and adjectives semantically by grouping lexical units that express the same concept into synsets and by defining semantic relations between these synsets. GermaNet has much in common with the English WordNet and can be viewed as an on-line thesaurus or a light-weight ontology.
Lancaster CQPweb: A web interface offering access to more than 50 corpora. We have licenses for most of them, so check which corpus you want and write us an email.
Linguistic Data Consortium (LDC): The Linguistic Data Consortium (LDC) is an open consortium of universities, libraries, corporations and government research laboratories. LDC has grown into an organization that creates and distributes a wide array of language resources. Browse their catalogue to see all the resources they make available, they provide many different resources.
Sentiment140: Sentiment140 allows you to discover the sentiment of a brand, product, or topic on Twitter. It is a corpus consisting of Tweets, annotated for their sentiment (positive, negative, neutral). Sentiment140 was created by Alec Go, Richa Bhayani, and Lei Huang, who were Computer Science graduate students at Stanford University.
The Kiel Corpus of Spoken German: Large-scale database of read and spontaneous speech, annotated for orthographic and phonetic (segmental and prosodic) features.
Tüba-D/Z: The Tübingen Treebank of Written German is a syntactically annotated newspaper corpus based on data of they daily newspaper "die tageszeitung". The syntactic annotation was performed manually.
For more corpora see https://www.clarin-d.net/en/corpora